This article will attempt to offer a detailed explanation about the obstacles one might find when trying to run OCA's queue_job on odoo's hosting platform odoo.sh.
At the time of this writing the queue_job can, in the words of an odoo.sh engineer, "somewhat work" with only one worker but is otherwise considered as not supported, see: odoo.sh FAQ.
As a result the only supported way to run queue_job at the time of writing is via a community module called queue_job_cron_jobrunner. It's a functional solution but it has several drawbacks and limitations outlined in the readme file of the module itself.We attempt to offer a bit more insight on what are the reasons behind this and what are the workarounds we currently took in order overcome them.
Configuration
First off to make the queue_job run on odoo.sh you must first add the configuration parameters to the config file which is at the time of this writing in `/home/odoo/.config/odoo.conf`
Use your favorite command line editor to add the queue_job config params as listed in the setup instructions and keep in mind that the default host and port (if unspecified) are localhost:8069. This does not apply to odoo.sh and you instead want to send job requests to the loadbalancer. At the very least, your configuration file should contain these parameters, pointing to the HTTPS URL set up for your build..
[queue_job]
scheme = https host = your-odoosh-url.odoo.com port = 443
To apply the new config changes run
odoosh-restart httpTerminology
Odoo.sh workers
Odoo.sh workers are different from the standard odoo workers. In odoo.sh one worker means one odoo process, multiple odoo workers mean multiple separate odoo processes that are not "aware" of eachother but they all connect to the same database similar to a multi-node deployment.
Jobrunner
The jobrunner is a separate thread initiated by the queue_job module when the Odoo server starts up. It establishes its own connection to the database and begins processing tasks from the queue_job table. These tasks, also known as jobs, are then dispatched to the Odoo HTTP worker for execution via HTTP requests. For more information, refer to: jobrunner
The problems
1. Odoo.sh cron worker
The first problem you will hit when deploying queue_job on odoo.sh in a production environment will be the fact that odoo.sh has 1 worker by default for http requests and 1 separate worker (process) for the cron operations.
The cron worker will spawn on a "best effort basis", execute the cron jobs needed and then exit. Given it runs on the same db and codebase as the http worker (queue_job module installed) it will also spawn a jobrunner like the active http worker. This means that, for the time when the cron is active (which depends on how many and/or long your cron operations are until the 15 minute timeout) you will have two active jobrunners that will both process queue_jobs and send them to the active http worker(s).
This results in a problematic situation where two jobrunners end up in a race condition, competing to handle the same tasks listed in the queue job table. Essentially, these are two separate processes fighting to manage the same queue state in their respective memories, and attempting to process identical jobs simultaneously. Imagine it as two generals shouting orders at the same group of soldiers.
2. Odoo.sh multiple http workers
When adding 2 or more more odoo.sh workers to your instance we have the same issue from above with two important distinctions:
a) An active HTTP worker is not automatically shutdown (if there is http traffic) and can increase in much higher numbers which make the effects above exponentially worse. This is also the main reason why odoo.sh lists the queue_job as unsupported on multiple workers and says it "somewhat works" with one (i.e meaning the situation isn't as problematic because the cron worker is just one extra jobrunner thread and it will eventually terminate).
b) The jobrunner should operate on just one odoo.sh worker but odoo.sh routinely recycles or restarts its workers so there should also be a backup or failover mechanism in place. This is essential for scenarios where the worker running the jobrunner might fail. A backup ensures that at least one jobrunner remains active, which is necessary for the queue to continue processing tasks.
With these specific traits we have a similar problem on our hands as with a multi-node deployment where multiple odoo processes (just like on odoo.sh) are connecting to the same database from different machines. They are not aware of eachother and neither knows if and when to take the lead and spawn the jobrunner. This challenge in computing is commonly referred to as leader election.
Here are two diagrams that explain the previous two points visually: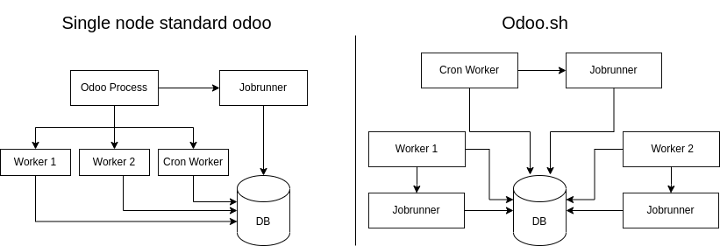
3. Odoo.sh http workers sleep
Whenever there is no http traffic odoo.sh puts the workers to sleep. If there are no more workers alive this means the jobrunner is also being shutdown. This should normally not be a problem because on startup the jobrunner grabs the open/waiting jobs and starts to process them but there are a few specific cases where this might be an issue such as:
a) You have jobs which are set to execute after a certain time and there is no http traffic until then. As the worker and jobrunner are both down there is no automatic execution and this will only resume when the http worker wakes up.
b) You add queue_job via a shell session, a scheduled action or some other way which does not bring up the http worker and thus there is no jobrunner to process it.
Workarounds
TLDR: https://github.com/pledra/odoo-sh
1. Suspend the jobrunner on cron workers
Our first order of business is to prevent the jobrunner from spawning whenever it detects that it is running on an odoo.sh cron worker. Ideally we would have something like an environment variable set or a config parameter (I hope someone from odoo.sh team reads this and makes our lives easier :D). Since we don't, we have to rely on some less robust and shaky methods of identifying the cron worker. Here are two:
a) The following command line args are always passed to the cron worker in both shared and dedicated instances "--max-cron-threads=0 --limit-time-real-cron=0 --limit-time-real=0". The HTTP worker on the other hand has values > 0 on these args.
b) It is launched from "/opt/odoo.sh/odoosh/bin/odoo-rpc" whereas the http worker is launched from "/home/odoo/src/odoo/odoo-bin"
While neither option is ideal we went with the first one and if we detect those parameters set to 0 we stop the jobrunner from initializing.
2. Run the jobrunner on only one http worker
Here a solution was proposed in the community to solve the leader election dilemma using postgresql advisory locks (link here). This however turned out to also not be supported by odoo.sh as mentioned in this comment on the same github issue.
Our approach was to assign a uuid to the jobrunner and include it in the application_name set in the database connection then apply a "first come first served" policy by checking the pg_stat_activity table. Every jobrunner verifies on init if he is the first one and if he is then he becomes a leader and initializes otherwise it will go into a holding pattern and check every 10 seconds which is the oldest connection. With this approach we have the following benefits:
- Workers do not have to communicate with eachother which one is the leader as the oldest entry in the pg_stat_activity table dictates this. The database becomes the one true source of automatic leadership election without any specific algorithm or lock which odoo.sh does not support.
- The likelihood of a race-condition between jobrunners is small as the connection data and order is handled by postgresql.
- If a worker/jobrunner should be terminated abruptly there is no need to do a liveness check or implement a heartbeat system to verify if the jobrunner is still active. Once the connection drops, for whatever reason, it can no longer process jobs and it can be considered out.
- Even if the shaky cron fix would fail because of future changes in odoo.sh there would still be no overlap of jobrunners, at worst just a leadership change.
- The solution does not require extra infrastructure for leadership election or a daemonized jobrunner script outside of the odoo process which is also against odoo.sh policy https://www.odoo.sh/faq?q=daemon#technical_limits
3. Uptime checks
The easiest way to prevent http workers from going to sleep is to use uptime check services like the one from google cloud which periodically checks the availability of the service behind a url. One should have this for monitoring anyway and it can serve as a keep-alive function for odoo http workers
Bonus feature
One other thing we ran into frequently was having to manually change the host config parameter in the odoo.conf file on staging builds after rebuilding from production. We monkeypatched the queue_job here as well and based on some available environment variables in the staging builds we changed this value dynamically with the one from the system parameters which is changed by default from odoo.sh.